
Modelos
O modelo define qual IA vai gerar as respostas do agente. No SquadOS, a escolha afeta qualidade, velocidade, custo, suporte a tools, imagens, arquivos e raciocínio.
Aba Modelo
Seção intitulada “Aba Modelo”Na aba Modelo do editor do agente, você vê três atalhos rápidos no topo e a lista completa de modelos abaixo. À direita, um painel detalha o modelo selecionado com janela de contexto, limite de output, custo em créditos por 1k tokens (input e output) e descrição.
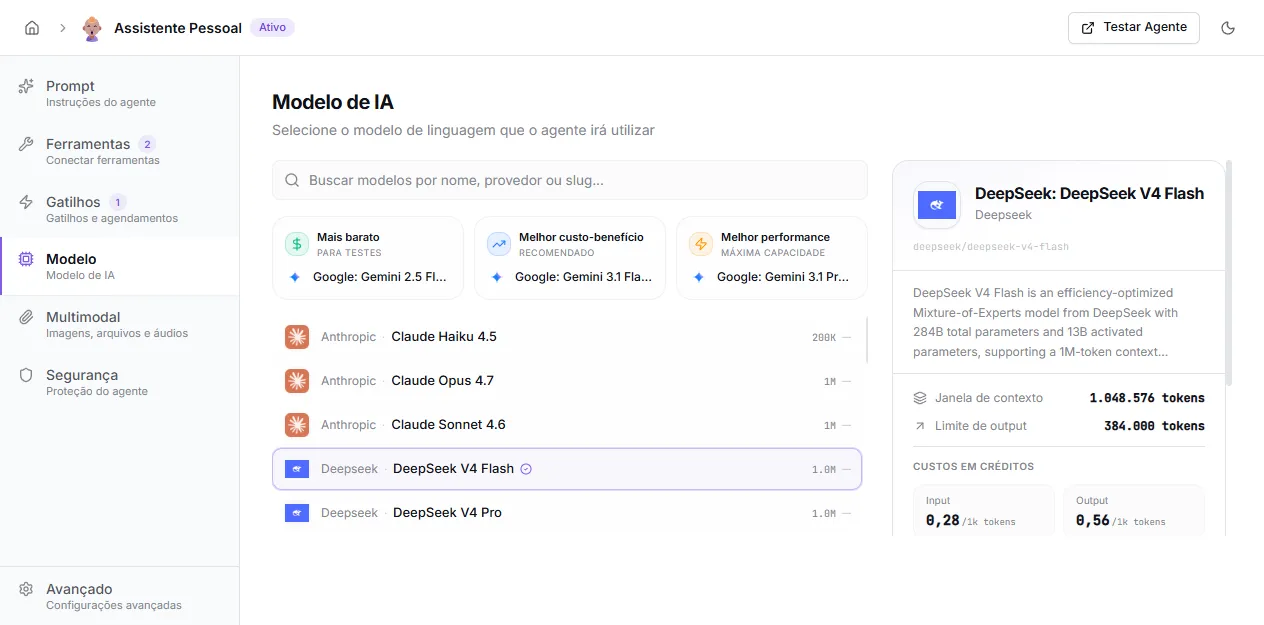
Atalhos rápidos
Seção intitulada “Atalhos rápidos”O SquadOS destaca três opções no topo da tela para acelerar a escolha:
- Mais barato — para testes: agentes simples, alto volume, prototipagem.
- Melhor custo-benefício — recomendado: opção equilibrada para uso geral. É o que vem pré-selecionado em agentes novos.
- Melhor performance — máxima capacidade: tarefas complexas, raciocínio multi-passo, contexto longo.
A composição desses três atalhos vem dos modelos disponíveis na sua organização e pode mudar quando a equipe SquadOS atualiza a tabela de modelos.
Lista completa
Seção intitulada “Lista completa”Use o campo Buscar modelos por nome, provedor ou slug para filtrar. A lista mostra provedor (Anthropic, OpenAI, Google, DeepSeek, etc.), nome do modelo e o tamanho da janela de contexto. Um clique seleciona — não precisa salvar manualmente; a escolha persiste automaticamente.
Painel de detalhes
Seção intitulada “Painel de detalhes”Quando você seleciona um modelo, o painel lateral à direita mostra:
- nome completo, provedor e slug (identificador técnico);
- descrição do modelo;
- janela de contexto (tokens de entrada);
- limite de output (tokens por resposta);
- custos em créditos por 1k tokens (input e output);
- ícones indicando se o modelo suporta visão (imagem) e arquivos.
O custo de cada turno de conversa é calculado por tokens enviados (input) + tokens gerados (output). Bases de conhecimento, histórico longo e prompts extensos aumentam o input.
Quando a organização usa chave OpenRouter própria (BYOK), o custo da chamada de texto vira 1 crédito fixo por turno — útil para volumes altos e modelos premium. Configure em Configurações → Modelos IA → Chave de API OpenRouter.
Para reduzir custo sem trocar o modelo, ajuste em Avançado:
- Limite de histórico: menos mensagens carregadas a cada turno.
- Limite de tokens por resposta: força respostas mais curtas.
- Multimodal: use pré-processamento com modelo barato para ler imagens, em vez de carregar tudo no modelo principal.
Suporte a ferramentas (tool calling)
Seção intitulada “Suporte a ferramentas (tool calling)”Praticamente todos os modelos modernos da lista suportam tool calling (function calling) — necessário para ferramentas nativas, HTTP customizadas e integrações. Se a aba Ferramentas mostrar comportamento estranho (a IA nunca chama tool), confirme que o modelo escolhido suporta tools.